
Over the past 20 years, I have on numerous occasions grabbed the latest demo copy (for some definition of “demo”) of AutoCAD or SolidWorks and sat down with it, determined to learn how to make things. For many years I have been aware of various CAM packages designed to help turn 3D models into tool paths for CNC machines, and more recently slicing software for turning 3D models into printable models. It seemed to me that a person could go out and buy a CNC mill or lathe and the requisite accessories, one could go buy CAM software, and then one could start making parts. Sure, you would probably send quite a bit of raw material and tooling to the recycler along the way in a teach-yourself-machining scenario, but you could start building stuff — especially simple things — almost immediately. Except… well, you needed a 3D model at the start of the whole process. The more you know the more you realize you don’t know. Obviously the “if I have a 3D model I can run!” concept is a gross oversimplification of every step, and disregards what one could spend an entire lifetime becoming really good at. When I first started thinking along these lines I was a teenager, optimistic and all-knowing.

At some point, this gem made it into my collection and has faithfully gathered dust next to a slew of programming reference manuals. The “For Dummies” book that I wasted $24.99 on at Borders in Rapid City, SD as a 21-year-old provided as evidence that when I say I have been wanting to CAD for 20 years — I’m not completely full of shit. Just mostly. There’s a point here: it DOES start with a model. You can prototype 1-off things by hand all day, but if you want the benefit of computer aided manufacture, whether you are adding material or subtracting it, you need to be able to model the resulting part. Your model may look a bit different based on the manufacturing method, but it sure as heck won’t look at all if you can’t build it. So this is the hard part, the mental gap, the crux.
It’s a whole new world now. When I buy reference manuals I find I don’t actually have time to read them cover to cover and absorb the knowledge, just use them for reference. I’m busy doing stuff, paying bills, being an adult. When did that happen? So I know myself well enough to know that if I want to learn something new, and fit it in, buying a book doesn’t cut it, I need a practical project to apply it to.


I have a few of these Milwaukee batteries around, and they are pretty good stuff. 54 Watt-hours in this specimen, 72 Watt-hours in another, that’s enough lithium stored ion fairy magic to do something serious. By comparison, my previous generation DeWalt power tool batteries were only in the 20-30 Watt-hour (Wh) ballpark.
There are lots of applications where I could use a good battery, bike lights, powering small electric DC motors, recharging my cell phone after too many hours watching YouTube videos, jump starting my motorcycle(s) every spring because I forgot to plug them into the battery maintainers… Lots! Milwaukee is obviously hip to this concept, as they sell a “Power Port” with a built-in inverter that snaps onto one of these M18 batteries and supplies a 5V USB port. There are a damn lot of cell phone charges in a 72Wh battery. Typical high capacity smartphone batteries are in the 10Wh ballpark. See also: Why Watt-hours
A few years ago I did a fair bit of work for a Rapid City company named B9Creations. They sell a 3D printer very popular among jewelers. As a result of that work, I learned enough about the competing 3D printing technologies to make what I felt would be an informed purchase decision, the ability to realistically weigh initial purchase price, consumable price, time spent on maintenance and configuration, print speed, build volume, etc. B9 sells a great product and if you can reasonably incorporate 3D printing into your job then you should probably consider buying one. SLA is rad. In my case, any 3D printer is going to sit next to my $49 InkJet (Ok, ok, $299 LaserJet) and very likely not get used at all once the novelty wears off. How much is the novelty worth? Not. Very. Much. That LaserJet is a bit of a novelty, the $49 InkJet would have been OK — so I guess if we do the math, the novelty is worth less than $300. My standards weren’t exactly that low, though, 100 micron build resolution? Yeah, that seems like a MINIMUM standard. 100mm/sec build speed? Again, minimal. The idea of it taking a full 24+ hours to build large/complex parts makes me roll my eyes and lose interest in a hurry.
Six months ago or so I stumbled across the Monoprice line of 3D printers. If you are unfamiliar with Monoprice, their business model is interesting and seems to fill a niche. They buy a bunch of something in a common specification, sell it at a very good price, and provide a reasonable level of service/support. So 1 option, not 37. No fancy packaging. Not straight from overseas so I can easily return it if I need to. This works for me and is a niche Amazon is also seeking to fill with products branded Amazon Basics.
For the last six months or so, I have had my eye on their V2 Mini printer, which comes in around the $200 mark, and has favorable reviews. My biggest concern was with the build volume, it’s also pretty slow. But, but.. $200! Fast forward six months, I noticed the “Maker Select Plus” model, which retails for $399 was available as a refurbished unit for a reasonable ($50) discount. I have always had good luck with refurbished equipment and am not afraid to give it a go so long as there is a reasonable length of time where I am able to return it. After deciding I could probably, maybe, possibly… justify this .. I noticed they had an “open box” version of the same model, which ostensibly is a unit that had been returned but had not gone through the refurbishment process, for $299. This printer and many other popular low-cost printers are based on an open source design. All of the parts are exposed, replacement parts are easy to source, and any problems shouldn’t be rocket science to diagnose. Bottom line: I can fix it or return it if it comes out of the box broken. Ok — fine. Printer ordered for $299.99, $0.01 below my novelty purchase threshold.
There is not TOO much to say about the unboxing and assembly, you can find that review somewhere else I am sure, but I will detail what was notable. The printer I received had obviously run some material through the nozzle but the build platform did not look used. Overall it was well packaged and was easily assembled. My problems began almost immediately after assembly, though. In total, I ended up with several hours into debugging, which is no big deal and I am still happy with my purchase. It’s hard to put the issues I ran into in context, to a person familiar with 3D printers or other multi-axis CNC equipment they may have diagnosed and fixed similar issues in ten minutes. Most people probably would have returned the printer out of frustration. The printer auto-homes at startup to sort of figure out what’s what and where everything is. I thought nothing of this auto-homing procedure to start, as I assumed any limit values for the three axis’s, axes, plural axe, would be hard coded in firmware somewhere, or something. This was ostensibly confirmed as there was a setting for the start positions of x, y, and z accessible via the touch-screen menu. After startup, it was nearly impossible to calibrate the build platform to get it perfectly level. The machine was also slightly bent from the prior owner trying to get this calibration done — fortunately not bent in a way to compromises the machine in any way, just gives it character aesthetically. After dinking around for a couple of hours I got it mostly sorted out, or so I thought. Then I noticed the quality of the first few layers of my part seemed to vary if the machine had been turned off and back on in-between prints. The only difference that would make is if the auto-home process was affecting something. One thing I found weird about the machine from the start, was the auto-home for the Z axis would touch down at a spot off the build platform, it was touching down on the bolt head used to secure the heated platform down, not on the print surface. I did not know if this was right or wrong, it just seemed odd. As it turns out, it was wrong. Depending on where it touched down on this rounded bolt head, it would throw off the first layers, or not. Dead in the center of the bolt head and my adjustment held, just slightly off center and everything was a mess. It all suddenly made sense. The build platform was moving too far during the auto-home process, and the machine was setting up configuration values based on where it stopped in this process. I adjusted the Y axis limit switch so the build table would stop slightly further toward the front of the printer. This resulted in the extruder always touching down on the actual build surface during auto-home. Boom. Easy to calibrate. Calibration held every time. Off to the races. I haven’t verified this is how the printer actually works in reality, for what it’s worth, I’m mostly just pulling all of this out of my rear. Tell me I’m full of it, I’ll probably believe you.
So I’m printing test prints downloaded from the internet. That’s cool, except there are a few million models I can download from all manner of different websites and they are all utter rubbish. Toys, novelties, trinkets. Mostly just trash though, really. The only ready-to-print models I have found so far that I expect to be useful are replacement parts for the printer… (Yeah, OK, so there’s a Milwaukee battery mount model out there already, but that’s beside the point)
On to the project at hand! Using these Milwaukee batteries for stuff other than making power tools spin! Shit. I’m back to needing a 3D model.
I spent a few days playing with various pieces of software. Some free, some not. Fusion 360 seems pretty capable for the price. I can see why TinkerCAD is popular, it is in fact quite easy to pull off basic things. I watched a bunch of videos. Lots. So many videos. I tried quite a few different things. I started to get the hang of it. Started being the key word. I sort of started getting my brain wrapped around this concept that I could draw things, and then apply fixed constraints to different pieces to make my imprecise drawings precise. Still, it all felt quite imprecise and clumsy. At this point, I knew one of the primitive operations the CAD platforms are all capable of doing is “extruding” a 2D shape into a 3D object. I couldn’t help but think about how much easier it would be to programmatically generate a vector, then import it into the CAD package to extrude it into a 3D shape. After years of tackling problems with algorithms, it was more natural to think about solving things this way. In programming we are often conceptually thinking about three dimensions, often times multiple three-dimensional data structures in addition to how the data structures interact with one another. Conceptually, this 3D modeling thing was easy. There I sat, though, in a GUI-driven CAD package able to model in my mind exactly what I wanted to do and how I should be able to go about it and unable to express that through the GUI. Frustrated. Tired. The novelty was wearing off quickly.
I didn’t want to give up, not this time, so I started looking at how I could script CAD tools to do some of what I wanted, programmatically, while I continued to learn the interface. Yep, in retrospect I was basically a rat in the bottom of a flushing toilet gasping for air, I had a lawn to mow and a room to paint and laundry to do and bills to pay, there was no time for this point-and-clickery.
Then I stumbled on Blender and its ability to be scripted with Python, OpenSCAD, and most interesting to me, OpenJSCAD. I almost didn’t pursue learning any of these tools. It seemed like the GUI-based modeling software/method is what everyone used, and perhaps these tools were just fringe software stacks of questionable quality. I watched more videos, I spent more time pointing and clicking. It still wasn’t clicking, though. Not having printed anything of my own creation yet, I finally broke down and sat down with an OpenJSCAD instance in one tab, the documentation in another, and a Milwaukee battery and digital caliper in my lap. I started taking measurements, I started creating shapes. I started merging shapes and subtracting them from one another. I made a whole bunch of mistakes, the code was a mess, I put the battery clips in the wrong place, I used the wrong units. I had a model though.
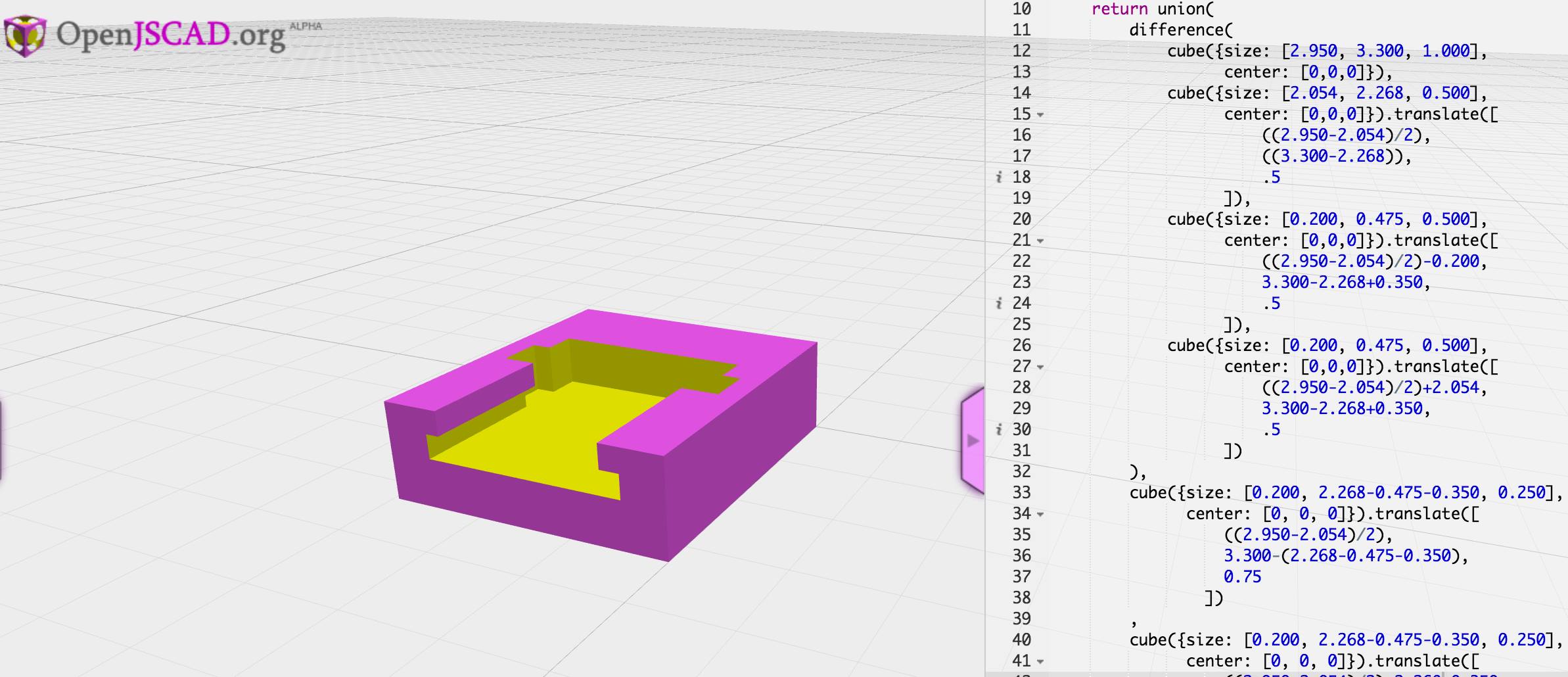
I slept on it, made some tweaks, and printed it to validate whether or not I could even slide a battery in and out. I was completely ignoring the electrical connections at this point. It printed, my battery didn’t fit. Easy to see why not though, I did another iteration. Printed, the battery still didn’t fit — but darn close! Iteration three, after learning about hull operations and how to radius things and… the model looks a lot better AND THE DAMN BATTERY FITS. I have printed 7 of these now, each with various tweaks that have been an improvement on the prior.





The most recent iteration (not shown) has electrical connectors and is fully functional. I have been quite impressed by the structural rigidity, strength, and light weight of the finished printed parts. You aren’t going to build passenger planes or rockets that can go to space with these parts, but for coming out of what is essentially a really precise hot glue gun they are amazing. Print #4 weighs 29 grams. It was printed with Monoprice PLA+ filament that was $19.99 for a 1kg spool. Material cost for this print? $0.58. Print time? About two hours. Would I trust it to hold onto my 1.5lb battery while it was repeatedly subjected to 3-4g’s? Yeah. Probably. It’s a functional part.
It has now been 1 month since I ordered the printer. OpenSCAD and OpenJSCAD have proven to be very rich environments for creating models. I find I am only limited by my ability to adequately express myself in code. This is the same limiting factor (mental leap) I found in GUI-based tools as well, but with the programmatic interface, I am able to bring my experience to bear on the problem. Sometimes my solutions lack elegance, but I can make it do what I want!
Developer? Want to model parts in 3D? Don’t do the clicky. Do what you do.
 MachForm (self hosted) is a great tool for managing many different types of user submissions from visitors to your website. While WordPress has a great form option in Gravity Forms, MachForm is platform agnostic and has a number of integration options allowing it to coexist fairly well with almost any LAMP-based web deployment.
MachForm (self hosted) is a great tool for managing many different types of user submissions from visitors to your website. While WordPress has a great form option in Gravity Forms, MachForm is platform agnostic and has a number of integration options allowing it to coexist fairly well with almost any LAMP-based web deployment.