
In 2009, Google introduced a method website owners could use to disambiguate duplicate content. By specifying a rel=canonical link element in the header of the page you give the search engine a hint as to the URL which should be authoritative for the given content. It should be noted Google has indicated they consider this method a hint, and not a directive. The conditions under which the hint will be ignored are not known, but such conditions are presumed to exist.
Imagine a simple example, anyone who has purchased a home or property in the US is reasonably familiar with the Multiple Listing System (MLS). Real estate agents add properties to the MLS and the exact same information shows up on the website of every agent and agency. How does Google know which website(s) are authoritative for this information if it is the same on potentially thousands of websites? This is a contrived example of a real-world problem, and implementing a strategy around canonical link elements can help to ensure people end up where you want them to be. One strategy might be to get visitors to the website of the agency, rather than the individual agents.
That information is all well and good, in theory, but how does it actually work in practice?
A tale of two websites…
Recently there was a case where a series of several dozen guest blogs on an established website needed to be moved, removed, or somehow re-incorporated into the overall strategy. The established site and its mission had grown and changed, meanwhile, the blog series in question had grown less relevant to the overall goals of the site. But it was still good content that many people accessed and used as a reference!
It was decided the content wasn’t “hurting” anything, and could remain, but would be inaccessible via primary navigation routes and should over the long term be given a new home. The original author of the blogs was willing to give the content a new, permanent, home on his own personal site. The authors site did not yet exist, had no existing inbound links, and zero authority with search engines — a blank slate!
Each blog post in question was re-posted on this new website, several dozen posts in total, a handful of which receive a reasonable amount of search engine traffic. The canonical links for the articles on the established site were then changed to reference these new pages on the formerly empty domain.
Google quickly adapted to the new “home address” of these pages, and within a matter of days, the new domain was seeing all the search engine impressions for these articles. After this quick adjustment over a period of a few days, the pattern held over the following month.
In the following graphic, a screenshot from the Google Search Console, you can clearly see the number of search engine impressions served by Google quickly ramped from 0 to in the neighborhood of 50 impressions per day.
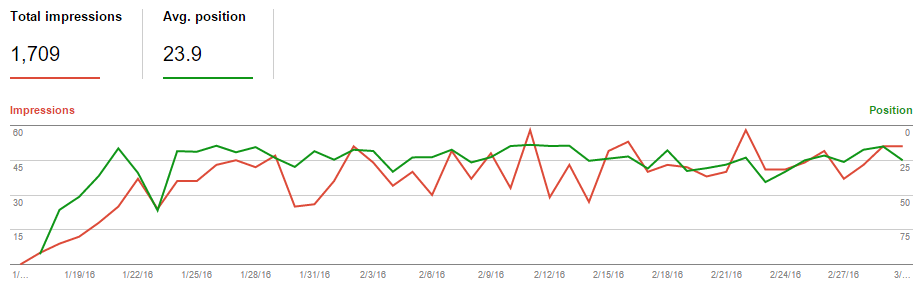
Here you can see the same data, over a slightly longer period, from the established site. The “new” site neatly stripped away around 10% of the organic search engine traffic from the established site.
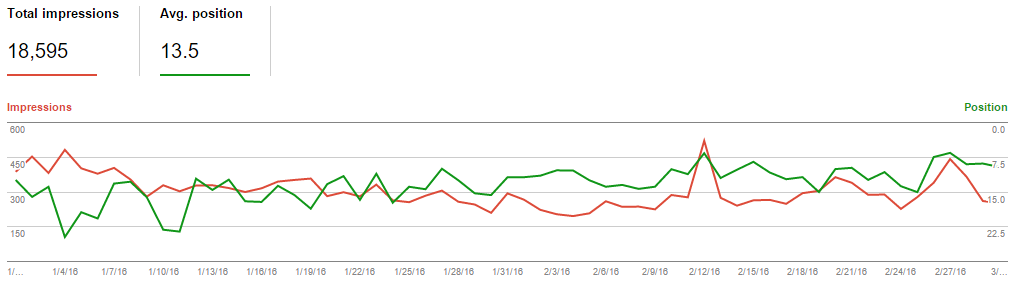
Most scenarios involving duplicate content management with the rel=canonical link element aren’t going to exactly match this one, so please take these results with a grain of salt. That said, it does clearly show the cause, effect, and timing surrounding changing the canonical links for established pages. It also clearly shows that Google pays attention to these canonical elements and can take fairly swift action on them.
